Präsenzveranstaltung mit bis zu 25 % Online-Anteil
Ist nicht kompliziert: Google & co meiden, Fachdatenbanken nutzen, Standort der Bücher & Zeitschriften lokalisieren, ausleihen & lesen. Man sollte wissen, wie man herausfindet, ob es sich um wichtige Zeitschriften bzw. Verlage handelt. Man braucht einige Methodenkenntnisse, um die Aussagekraft wissenschaftlicher Studien bewerten zu können. Hilfreich sind vielleicht auch Kenntnisse darüber, was in Veröffentlichungen wo steht, damit man nicht alles von vorn bis hinten lesen muss. Aber das war´s dann auch. Die Veranstaltung führt ein in die Datenbankrecherche.
Diese Veranstaltung richtet sich an Studierende der Sozialen Arbeit im Modul 1.1 des ersten Semesters.
Erste Sitzung
In der ersten Sitzung stelle ich mich und die Veranstaltungsplanung vor. Sie erfahren von mir, welche Standards gelten, wenn Sie sich für eine modulabschließende Prüfung bei mir entscheiden wollen. Und dann geht es gleich zur Sache: Ich erkläre, wie man eine Fragestellung entwickelt. Und dann unternehmen Sie erste Schritte in diese Richtung, wenn Sie wollen könnten Sie sogar versuchen eine Fragestellung zu entwickeln, die Sie im Rahmen einer späteren Hausarbeit untersuchen wollen.
Es gibt verschiedene Wege eine Hausarbeit zu schreiben. Sie können z. B. eine Hausarbeit schreiben, die herausfinden will, welche Angebote eine/r Ihrer Adressat*innen braucht, um erste Schritte zu tun, ein wichtiges Problem anzugehen (diagnostische Hausarbeit). Sie können auch eine klassische Hausarbeit schreiben. Wichtig ist hier erstens, dass Sie auf irgendeine Art und Weise nicht nur zusammentragen, was andere geschrieben haben, sondern auch analysieren und interpretieren. Dies kann man normalerweise tun, indem man in irgendeiner Weise einen Vergleich einbaut (z. B. Vergleich von Methoden, Vergleich von Ländern, Vergleich von Epochen).
Zweite Sitzung
Die zweite Sitzung befasst sich damit, welche Probleme entstehen, wenn man googelt oder wenn man eine Katalogrecherche mit einer Fachdatenbankrecherche verwechselt. Damit dies anschaulich wird, werden die Teilnehmer*innen gebeten, auf eigenen Geräten eine schlechte Recherche durchzuführen. Wie Sie vermutlich alle wissen, zeigt Google ja nicht an, was zu Ihrem Thema veröffentlicht ist. Sondern Google entwirft auf Basis Ihrer Suchgeschichte und Ihrer Käufe im Internet Hypothesen darüber, was Sie interessieren könnte und zeigt Ihnen dann nur noch passende Treffer an. Diese Personalisierung führt zu vielfältigen Problemen, u.a. auch dazu, dass Sie ggf. nicht erkennen, dass Fragen kontrovers diskutiert werden oder dass Sie sich nur einseitig informieren.
Um herauszufinden, was alles passieren kann, werden die Teilnehmer*innen gebeten, mit ihren eigenen Endgeräten zum Thema Autismus-Therapie zu recherchieren. Die Auswertung soll erstens die verrücktesten Treffer zusammenstellen. Zweitens wird untersucht, ob es seriöse Treffer gibt und in welcher Hinsicht sich diese vom aktuellen Stand der Forschung unterscheiden.
Die Suche nach unseriösen Seiten war sehr erfolgreich. Gefunden wurde etwa der Vorschlag mit Chlordioxid Autismus zu heilen. Autismus muss man auch als Reinkarnationsproblem verstehen. Und es empfiehlt sich, eine Stuhltransplantion in der Therapie von Autismus einzusetzen. Na klar: Diese Vorschläge sind irre und für die meisten Studierenden klar als Nonsens erkennbar. Das Problem ist aber: Es gibt offenbar genug Eltern, die auf derlei Unsinn hereinfallen.
Hier ein Podcast aus einer Veranstaltung des letzten Semester zum Thema „Falsch Recherchieren“:
Die Probleme von Google sind also: Google Recherchen sind personalisiert und damit nicht nachvollziehbar. Sie stellen nur eine tendenziöse Auswahl zur Verfügung. Und sie schließen seriöse, urheberrechtsgeschützte Seiten aus.
Dritte Sitzung: Mit Datenbanken recherchieren
Gesucht wird also ein Werkzeug, das einen nicht personalisierten Überblick über alle relevanten Veröffentlichungen zum Recherchethema verschafft und einen möglichst hohen Anteil von fakewissenschaftlichen Publikationen ausschließt. Dieses Werkzeug sind Fachdatenbanken. Fachdatenbanken bieten allerdings diese Vorzüge in unterschiedlichem Maße. Grundsätzlich kann man sagen: Je schwieriger es ist, Publikationen in diese Fachdatenbanken zu bringen, desto geringer ist der Anteil von Müll. Es ist z. B. vergleichsweise schwierig, Publikationen in pubmed.ncbi oder pubpsych de unterzubringen. Und es ist vergleichsweise leicht, Beiträge in FIS-Bildung unterzubringen. Der Anteil von unseriösen Beiträgen in FIS-Bildung ist also deutlich höher.
Man sollte auch darauf hinweisen, dass auch unseriösen Beiträgen gelegentlich eine Publikation gelingt, die von pumbmed.ncbi oder pubpsych de aufgenommen werden. Und auch seriöse Datenbanken haben ein Problem mit gesponserten Beiträgen. Da sind dann z. B. Ministerien, die nicht neutral informieren wollen, sondern vor allem ihre Politik in einem günstigen Licht darstellen wollen. Die Bundesagentur für Arbeit möchte Arbeitslose verstecken oder z. B. über die berufliche Inklusion von Menschen mit Behinderungen irreführende Informationen verbreiten. Die Pharmaindustrie kauft gerne Forschende. Und es gibt leider auch Anhänger*innen wenig wirksamer Methoden, die auf der Suche nach neuen Jüngern sind.
Dennoch überwiegen die Vorteile von Fachdatenbanken klar. Denn hier bekommt man einen nachvollziehbaren Überblick über den Stand der Forschung und keine tendenziöse Auswahl. Und der Anteil an unseriösen Positionen ist geringer.
Hier ein passender Podcast aus den vergangenen Semestern:
Datenbankrecherche
Vierte Sitzung (24.4.) / Online-Sitzung
In der vierten Sitzung steht die Bewertung der Treffer aus der Datenbankrecherche auf dem Programm. Denn man muss sich gut überlegen, welche Treffer man beschaffen will, und welche eher nicht. Dabei gibt es zulässige und nicht zulässige Strategien. Und es bestehen nicht ganz unerhebliche Gefahren, auf Veröffentlichungen aus Predatory Journals hereinzufallen oder Kongressberichte in die Literaturliste aufzunehmen, die aus Kongressen stammen, die problematische Veranstalter haben. Bei Zeitschriften und Büchern ist es sinnvoll, auch die Verlage zu prüfen. Haben die Verlage ein einschlägiges Programm? Handelt es sich um Verlage, die gegen Geld alles drucken? Natürlich muss man dabei damit rechnen, dass derlei Verlage ihre Homepage so gestalten, als sei alles normal. Die Behauptung, man praktiziere ein Peer-Review-Verfahren, lässt sich ziemlich einfach publizieren. Überprüfen kann man das aber nicht so ohne weiteres.
Hier nun ein passender Podcast aus dem letzten Semester:
Minions schlägt vor: Schmidt, S. : Konstruktion, Normierung und Validierung des ADHS Screenings für Erwachsene. Bremen 2009
Kommentar Mand: Es handelt sich um eine Dissertation. Kann man gut verwenden.
Fünfte Sitzung
Viele Datenbanktreffer sind nicht frei verfügbar. Also ist es sinnvoll, Zeitschriftenbeiträge oder Bücher in den Bibliotheken der Region auszuleihen. Auch hier ist ein bibliotheksübergreifendes Vorgehen sinnvoll. Denn , dass eine Bibliothek wirklich alle benötigten Zeitschriften oder Bücher hat, ist doch ziemlich unwahrscheinlich.
Hier der passende Podcast aus dem letzten Semester. Bitte beachten Sie, dass Sie hier beim Nachvollziehen der Recherche zu anderen Ergebnissen kommen können. Denn in den letzten sechs Monaten hat sich durchaus einiges getan. Die Werkzeuge sind aber immer noch dieselben: Bücher findet man mit überregionalen Bibliothekskatalogen. In NRW empfehle ich den HBZ Verbundkatalog. Und Zeitschriften findet man mit der (deutschlandweit arbeitenden) Zeitschriftendatenbank. Und auch das Vorgehen bei der Suche hat sich nicht geändert. Einige Bibliotheken haben sich aber neue Bücher gekauft oder Zeitschriften abbestellt.
Bücher und Zeitschriften in Bibliotheken der Region finden
Sechste Sitzung
Die sechste Sitzung erklärt an einem Beispiel, wie man empirische Studien bewertet. Wichtig ist zunächst die Stichprobe.
Hier ein passender Podcast aus dem vergangenen Semester.
Siebte Sitzung
Die Bewertung von Studien ist eine Sache, die man üben sollte. Entsprechend schauen wir uns gemeinsam einige Studien an, auf die Sie vielleicht im Rahmen Ihrer Recherche gestoßen sind.
Wir haben uns zunächst den quantitativen Teil der gerade in den Medien breit diskutierten KviAPol Studie angeschaut (Abdul-Rahma, Grau, Klaus & Singelnstein (2020): Zweiter Zwischenbericht zum Forschungsprojekt „Körperverletzung im Amt durch Polizeibeamt*innen“ (KviAPol). Rassismus und Diskriminierungserfahrungen im Kontext polizeilicher Gewaltausübung. Ergebnis: Die Studie hat ein massives Stichprobenproblem. Offenbar wurden alle möglichen Wege beschritten, Menschen zur Teilnahme zu bewegen: Genannt werden die Verteilung über Gatekeeper und Öffentlichkeitsarbeit. Wer von der Studie gehört hat und irgendwie interessiert war, konnte teilnehmen. Das ist sicher kein Weg zu repräsentativen Zahlen, wie auch die Autor*innen zugestehen. Der Zwischenbericht unterscheidet zwischen Persons of Colour und Weißen. Aber nicht Persona of Colour, sondern vor allem Weiße nehmen an der Studie teil – in erheblichem Umfang wohl Ultras und Punks.
Das zweite Problem teilt die KviAPol-Studie mit vielen Online-Studien. Die Aussagekraft einer Studie bemisst sich u. a. am Rücklauf, also dem Anteil der Menschen, die um eine Teilnahme an der Studie gebeten wurden und auch tatsächlich teilnehmen. In dieser Studie ist vollkommen unklar, wie viele Menschen die Option wahrgenommen haben, an der Studie teilzunehmen und welcher Anteil dieser Menschen sich gegen eine Teilnahme an der Studie entschieden hat. Verlässliche Angaben zum Rücklauf fehlen also. Ich würde tippen: Die Zahlen bewegen sich im Promille-Bereich.
Man kann also bestenfalls festhalten: Es gibt in Deutschland wohl einige Menschen, die sich von der Polizei diskriminiert fühlen, offenbar auch Ultras und Punks. Ob sie tatsächlich diskriminiert wurden, ist unklar. Manche dieser Menschen haben an der Studie teilgenommen. Wie viele das sind und welche Anteile auf eine Anzeige verzichtet haben, weiß niemand, auch nicht die Autor*innen. Und da hilft der Stichprobenumfang, auf den bei der Vermarktung der Studie offenbar mit großer Freude hingewiesen wurde, leider überhaupt nicht weiter.
Hätte man die Studie auch anders durchführen können? Ein Weg zu aussagefähigen Befunden hätte über eine Klumpenstichprobe an Berufsschulen und Schulen mit Oberstufen führen können. Man hätte hierfür lediglich ein Verzeichnis aller betreffenden Schulen erstellen müssen und dann mit Zufallszahlen die Schulen auswählen müssen, die um eine Mitwirkung gebeten wurden. Na klar, das ist eine bestimmte Altersgruppe, die befragt werden würde. Aber es handelt sich ganz klar um eine für die Fragestellung relevante Altersgruppe. Wer so vorgeht, bekommt das, was eigentlich interessant ist: Repräsentative Zahlen zum Thema Diskriminierung und Rassismus in der Polizeiarbeit.
Achte Sitzung
Auch die achte Sitzung befasst sich mit der Bewertung von Studien.
Neunte Sitzung
In der neunten Sitzung erkläre ich zunächst, was ein Korrelationskoeffizient ist. In einem zweiten Schritt schauen wir uns eine Studie an, die mit Korrelationskoeffizienten arbeitet.
Wie Korrelationskoeffizienten funktionieren
Ein erstes Beispiel für Korrelationsstudien finden Sie auf dieser Homepage. Unter Online-Publikationen habe ich eine kleine Studie veröffentlicht, die ich mit Studierenden dieser Hochschule angefertigt habe, um festzustellen, ob Kinder mit nicht deutscher Staatsbürgerschaft häufiger in Förderschulen NRWs anzufinden sind (Je mehr ausländische Schüler desto mehr Förderschüler).
Das ist nicht das erste Mal, das ich der Frage nachgegangen bin, ob kommunale Daten wie Arbeitslosenquote oder Anteil von Bürgern nicht deutscher Staatsbürgerschaft Auswirkungen auf Förderschulquoten haben. Den Anfang macht eine Studie, die ich 2006 in der Zeitschrift für Heilpädagogik veröffentlich habe (Mand, J.: Integration für die Kinder der Mittelschicht – Förderschulen für die Kinder der Arbeitslosen und Ausländer). Und Anfang des Jahres 2023 lassen sich noch immer solche Zusammenhänge finden.
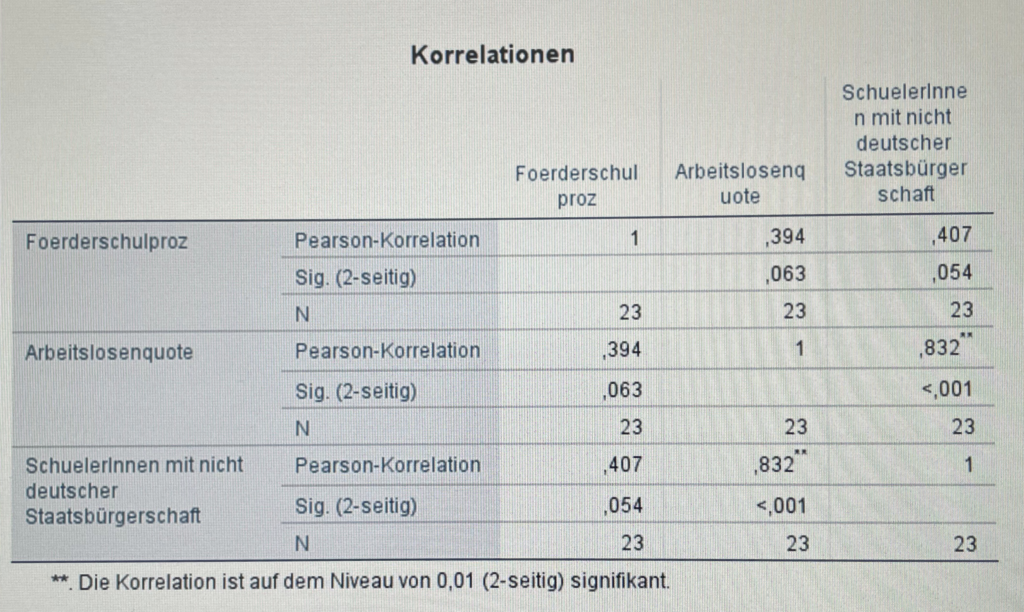
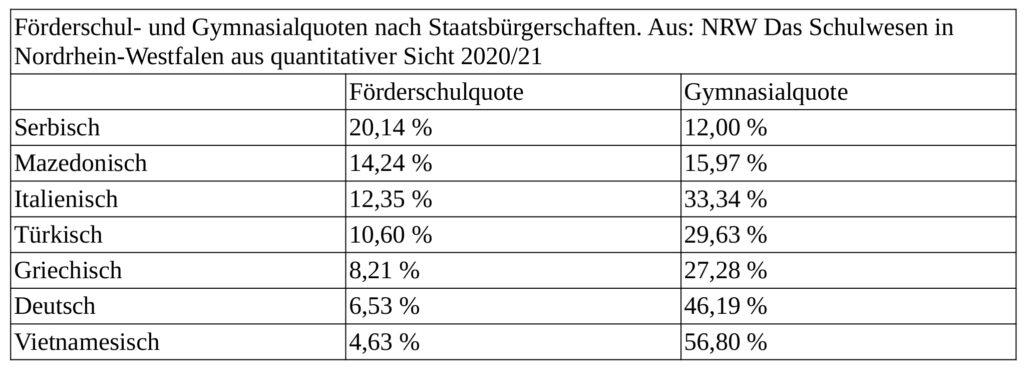
Bevor Sie aber auf die Idee kommen, dass es hier wirklich allein um Staatsbürgerschaft geht, habe ich hier für Sie noch eine Tabelle, die ich für eine Fortbildung in Gelsenkirchen im Mai dieses Jahres berechnet habe. Kinder mit nicht deutscher Staatsbürgerschaft schneiden sehr unterschiedlich in Schulen NRWs ab. Am schlechtesten der hier untersuchten Nationen schneiden Kinder mit serbischer Staatsbürgerschaft ab. Besser als die Kinder mit deutscher Staatsbürgerschaft sind die Schüler mit vietnamesischer Staatsbürgerschaft. Staatsbürgerschaft steht also für irgend etwas anderes. Haben Sie eine Idee, was das sein könnte?
Zehnte Sitzung
In der zehnten Sitzung geht es um Cohen´s Effektstärke (Cohen´s d) Denn es ist schon sinnvoll, dass man auch dann prüfen kann, wie stark eine Intervention ist, wenn die Autor*innen der jeweiligen Studien dies nicht tun. Was braucht es hierfür? Benötigt werden Studien, die zwei Stichproben vergleichen (z. B. Studien mit Versuchs- und Kontrollgruppe). Man braucht das Arithmetische Mittel. Und man braucht die Standardabweichung zumindest der Kontrollgruppe. Dies sind Werte, die in Studien üblicherweise mitgeteilt werden. Weil die Effektstärke so einfach auch im Nachhinein berechnet werden, arbeiten viele Meta-Analysen mit diesem Kennwert.
Hier kommt ein Podcast aus meinem Fundus, der Cohen´s d erklärt:
Elfte Sitzung: Kausale Beziehungen (Online Sitzung; 19.6.)
Das ist ziemlich häufig, dass man versucht, in Forschungsprojekten Hinweise auf kausale Beziehungen zu ermitteln. Man betrachtet die Bildungsverläufe von Kindern aus Armutsfamilien, weil man glaubt, dass Kinder aus Armutsfamilien deshalb so schlecht im deutschen Bildungssystem abschneiden, weil sie arm sind. Oder: Man vergleicht behinderte Kinder aus inklusive Schulen mit behinderten Kindern in Förderschulen, weil man glaubt, dass behinderte Kinder in inklusive Schulen deshalb bessere Leistungen zeigen, weil sie in der Inklusion gefördert werden. Beide Vermutungen sind übrigens keineswegs so offensichtlich belegt, wie man meinen kann. Es stimmt zwar, dass Kinder aus von Armut betroffenen Familien schlechter in der Schule abschneiden, als z. B. Kinder aus Akademikerfamilien. Aber erstens entstehen solche Zusammenhänge ja nicht daraus, dass alle Kinder aus von Armut betroffenen Familien in den Förderschulen landen. Sondern auch die Kinder von aus Armut betroffenen Familien besuchen zu ganz überwiegenden Anteilen die Regelschulen. Und man kann auch nicht sagen, dass gut belegt wäre, dass Inklusionsschulen behinderte Kinder besser fördern als Förderschulen. Die Leistungsunterschiede sind zwar gut belegt. Aber gleichzeitig deutet sich an, dass Inklusion eher eine Veranstaltung für die Kinder der Mittelschicht sein könnte. Die Inklusionskinder könnten also zu ganz erheblichen Teilen auch deshalb besser abschneiden als Förderschulkinder, weil sie von ihren Mittelschichtseltern besser gefördert werden.